
iOS HTTP cache analysis for abusing APIs and forensics
We’ve tested a number of iOS apps in the last few years, and got to the conclusion that most developers follow the recommendation to use APIs already in the system – instead of reinventing the wheel or unnecessarily depending on third party libraries. This affects HTTP backend APIs as well, and quite a few apps use the built-in NSURLRequest class to handle HTTP requests.
However, this results in a disk cache being created, with a similar structure to the one Safari uses. And if the server doesn’t set the appropriate Cache-Control headers this can result in sensitive information being stored in a plaintext database.
Like others in the field of smartphone app security testing, we’ve also discovered such databases within the sandbox and included it in the report as an issue. However, it can also be helpful for further analysis involving the API and for forensic purposes. Still, there were no ready to use tools, which is problematic in such a convoluted format.
The cache can usually be found in Library/Caches/[id]/Cache.db where [id] is application-specific, and is a standard SQLite 3 database, as it can be seen below.
$ sqlite3 Cache.db
SQLite version 3.12.1 2016-04-08 15:09:49
Enter ".help" for usage hints.
sqlite> .tables
cfurl_cache_blob_data cfurl_cache_response
cfurl_cache_receiver_data cfurl_cache_schema_version
Within these tables, all the information can be found that can be used to reconstruct the requests issued by the app along with the responses. (Well, almost; in practice, the lack of HTTP version and status text is not a big problem.)
Since we use Burp Suite for HTTP-related projects (web applications and SOAP/REST APIs), an obvious solution was to develop a Burp plugin that could read such a database and present the requests and responses within Burp for analysis and using it in other modules such as Repeater, Intruder or Scanner.
As the database is an SQLite one, the quest began with choosing a JDBC driver that supports it; SQLiteJDBC seemed to be a good choice, however it uses precompiled binaries for some platforms, which limits its compatibility. After the first few tests it also became apparent that quite a few parts of JDBC is not implemented, including the handling of BLOBs (raw byte arrays, optimal choice for storing complex structures not designed for direct human consumption). The quick workaround was to use HEX(foo) which results in a hexadecimal string of the blob foo, and then parsing it in the client.
BLOBs were used for almost all purposes; request and response bodies were stored verbatim (although without HTTP Content Encoding applied, see later), while request and response metadata like headers and the HTTP verb used were serialized into binary property lists, a format common on Apple systems. For the latter, we needed to find a parser, which was made harder by the fact that most solutions (be it code or forum responses) expected the XML-based representation (which is trivial to handle in any language) while in this case the more compact binary form was used. Although there are utilities to convert between these two (plutil, plistutil and others), I didn’t want to add an external command line dependencies and spawn several processes for every request.
Fortunately, I found a project called Quaqua that had a class for parsing the binary format. Although it also tried converting the object tree to the XML format, a bit of modification fixed this as well.
With these in place, I could easily convert the metadata to HTTP headers, and append the appropriate bodies (if present). For UI, I got inspiration from Logger++ but used a much simpler list for enumerating the requests, since I wanted a working prototype first. (Pull requests regarding this are welcome!)
Most of the work was solving small quirks, for example as I mentioned, HTTP Content Encoding (such as gzip) was stripped before saving the body, however the headers referred to the encoded payload, so both the Content-Length and the Content-Encoding headers needed to be removed, and former had to be filled based on the decoded (“unencoded”) body.
Below is a screenshot of the plugin in action, some values had been masked to protect the innocent.
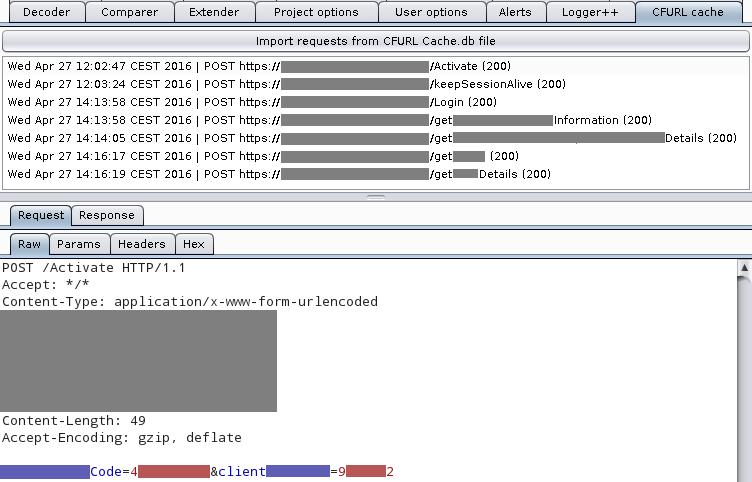
The source code is available on GitHub under MIT license, with pre-built JAR binaries downloadable from the releases page.
Featured image is Apfelteiler by Frank C. Müller licensed under CC BY-SA