Emulating custom crytography with ripr
Custom cryptography and obfuscation are recurring patterns that we encounter during our engagements and research projects. Our experience shows that despite industry best practices and long history of failures these constructs are not getting fixed without clear demonstration of their flaws. Most of the time demonstration requires instrumenting the original software or reimplementing the algorithms from scratch. This way we can create specially crafted encrypted messages, find hash collisions etc.
Ripr is a really exciting tool “that automatically extracts and packages snippets of machine code into a functionally identical python class backed by Unicorn-Engine”. I was really curious about how effectively this tool can be used so I decided to create a new sample that models some of the algorithms we’ve seen and write up my experiences as a reference for others.
The test program
To put ripr to the test I grabbed the first decent looking RC4 implementation in C* and added an additional XOR step with a hardcoded 4-byte key to it. This small addition would simulate hardcoded keys, lookup tables and other constants that are commonly used in standard and non-standard algorithms alike. As we will see, resolution of these structures is not a trivial task for a static analyzer.
I compiled the code with GCC, not stripping the symbols, so I could work as if I already did the reversing work to identify the subroutines of interest. I then loaded the binary to Binary Ninja and made ripr export the key scheduler (KSA) and the keystream generator (PRGA) functions as two Python classes that I copied to a single script. As this was in the middle of a busy day I just slapped some instantiation code to it to see if the thing runs without any obvious compilation errors.
ksa=KSA() # Instanitate key scheduler
ksa.run(key,S) # initialize cipher state (S) with key
print repr(S)
prga=PRGA() # Instantiate keystream generator
prga.run(S,plain,cipher) # Run keystream generator with the calculated state
print repr(cipher)
It did, but in order to make the code do anything useful we need to understand what was and what wasn’t generated for us by ripr.
* I didn’t verify the correctness of this implementation and even noticed some oddities (like calculation of the ciphertext size), but any mistakes would make my candidate even better for a “homebrew” algorithm.
First commit (e1569ae)
The first thing I noticed is that the generated code doesn’t handle output arguments: Arguments are just written to the memory of the emulator, but ripr doesn’t know that some of these allocations will contain important data at the end of the run of the function. This can be easily fixed by reading memory from addresses pointed to by the argAddr_N variables. In our case the key scheduler populates the S buffer, so we have to read back the memory of arg_1 of KSA.run():
- return self.mu.reg_read(UC_X86_REG_RAX)
+ return self.mu.mem_read(argAddr_1,256)
As you can see I chose to implement more “pythonic” interface for this method, returning the object of interest instead of using an output variable. You can see similar changes in the later commits where I’m finalizing the code.
When I executed this code the KSA function executed successfully (but not necessarily correctly!) but the PRGA raised the following exception:
Traceback (most recent call last):
File "prga.py", line 115, in <module>
prga.run(S,plain,cipher)
File "prga.py", line 57, in run
self._start_unicorn(0x400733)
File "prga.py", line 44, in _start_unicorn
raise e
unicorn.unicorn.UcError: Invalid memory write (UC_ERR_WRITE_UNMAPPED)
Second commit (aaf375c)
It seems that the emulated program tries to access unmapped memory. Since the exception is caused by emulated code, the stack trace doesn’t provide information about what exactly went wrong. To debug this we need to know the instruction and the context where the emulation fails. One way to do this is to hook each instruction in Unicorn Engine but for me it was easier to extend the auto-generated exception handler code to print out context information when an unhandled exception happens:
else:
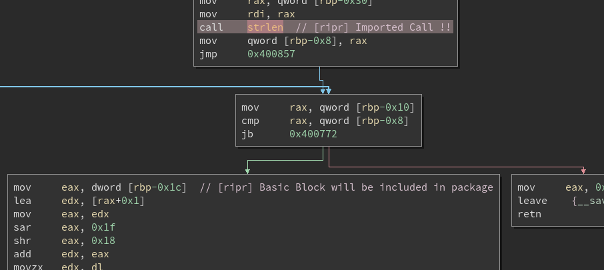
+ print "RIP: %08X" % self.mu.reg_read(UC_X86_REG_RIP) # 0x4007dd: mov eax, dword [rbp-0x1c]
+ print "EAX: %08X" % (self.mu.reg_read(UC_X86_REG_EAX))
raise e
The offending instruction can be seen as comment above. EAX pointed to memory at slightly above 0x4000 so I simply added a new mapping to the constructor of PRGA and the exception went away:
+ self.mu.mem_map(0x1000 * 4, 0x1000) # Missed mapping
After looking at the exception handlers I also tried to implement strlen() as a hook function that is meant to replace the original import call during emulation. Hooks for impoerted functions work by checking memory access exceptions against a defined list of addresses: if the saved return address points after an imported function call, the generated code handles the exception by calling the corresponding hook function. As far as I can tell return values should be manually set in the hook function (in this case setting EAX to the string length), but I also gave the function a return value for easier debugging (it turned out my original code had a pretty obvious bug, can you spot it?).
Third commit (5680b36)
So the code ran fine, but the results were different from what I got from the original binary. Two things were suspicious though:
- My static obfuscator string (“ABCD”) was nowhere to be found in the generated code. This shows that manual reverse engineering is still crucial when using ripr.
- My
strlen()implementation was never called. Since hook functions are really easy to write, I suggest to always add some debug code (even simple prints) to them to prevent bugs like this. This is also a good way to have a high-level trace of the execution of the emulator.
With enough infromation obtained by reversing the program the first problem can be resolved easily. In this case I also had a suspicious piece of memory in the generated code that I couldn’t originally connect to anything:
self.data_0 = '00000000000000000000000000000000540a400000000000'.decode('hex')
It turns out that my obfuscator key is located at 0x400a54. This piece of memory held the pointer to it, but that region was not properly populated (although it was mapped so it didn’t cause an exception). Similarly, the import for strlen() was located at 0x4004d0 in the original binary, but not populated in the generated code by ripr. Adding these two lines to the PRGA constructor resolved these issues:
self.mu.mem_write(0x400a54L, "4142434400".decode('hex'))
self.mu.mem_write(0x4004d0L, "ff25410b2000".decode('hex'))
Note that the code written for the strlen() import is just a jump pointing to some memory unmapped in the emulator. This way an exception will be raised that can be handled by the code responsible for calling the hook function in Python.
Fourth commit (c9c7d3c)
What I failed to notice before this commit was that KSA also relied on strlen(). But since it was in a separate class using a different emulator instance my previous changes didn’t affect it. One could merge the classes, but for the sake of simplicity I chose to just duplicate the code. After this the emulated and the original program gave identical results.
Conclusion
All in all I managed to create a working emulator in about two hours, without any prior experience with ripr. Assuming proper understanding of the targeted program I expect about the same effort needed for experienced users in case of real life targets: the complexity of the task is mostly dependent on the number of unresolved data and code references, not the complexity of the algorithm itself. Considering the amount of work needed to reimplement cryptographic code, or instrumenting large software, ripr will definitely be on the top of my list of tools when the next homebrew crypto-monster appears!