
Adding XCOFF Support to Ghidra with Kaitai Struct
It’s not a secret that we at Silent Signal are hopeless romantics, especially when it comes to classic Unix systems (1, 2, 3). Since some of these systems – that still run business critical applications at our clients – are based on some “exotic” architectures, we have a nice hardware collection in our lab, so we can experiment on bare metal.
We are also spending quite some time with the Ghidra reverse engineering framework that has built-in support for some of the architectures we are interested in, so the Easter holidays seemed like a good time to bring the two worlds together.
My test target was an RS/6000 system running IBM AIX. The CPU is a 32-bit, big-endian PowerPC, that is already (mostly?) supported by Ghidra, but to my disappointment, the file format was not recognized when importing one of the default utilities of AIX to the framework. The executable format used by AIX is XCOFF, and as it turned out, Ghidra only has a partial implementation for it.
At this point I had multiple choices: I could start to work on the existing XCOFF code, or could try to hack the fully functional COFF loader just enough to make it accept XCOFF too, but none of these options made my heart beat faster:
- Java doesn’t have unsigned primitives, that makes parsing of byte streams painful
- The existing ~1000 LoC XCOFF implementation includes a wide set of structure definitions with basic getters and setters, but it doesn’t handle more complex schematics of the input
- The COFF loader expects everything to be little-endian – adding support for BE would require rewriting everything
Instead, I decided to start from scratch, and develop code, that:
- is reusable in tools other than Ghidra
- is easy to read, write and extend
- has excellent debug tools
Ghidra ❤️ Kaitai
The above benefits are provided by Kaitai Struct, “a declarative binary format parsing language”. Instead of implementing a parser in a particular (procedural) language and framework, with Kaitai we can describe the binary format in a YAML-like structure (I know, YAML===bad, but believe me, this stuff works), and then let the Kaitai compiler produce parser code in different languages for us from the same declaration.
Although my Kaitai-fu (picked up mainly through these challenges at Avatao) was rusty , I managed to put together a partial, hacky, but working format declaration in a couple of hours for XCOFF32, based on IBM’s documentation.
This approach also had some benefits from research standpoint, as by reading the specification I could spot
- inconsistencies between specification and implementation
- redundant information (e.g. size specifications) in the spec
both of which can lead to interesting parsing bugs! (After this, I wasn’t surprised, when while digging Google I found that IDA, which has built-in XCOFF support has suffered from such bugs in the past)
Coming back to Ghidra development, I could create two implementations from the same Kaitai structure: one in Python, one in Java. I could import the Java implementation as a class in my Ghidra Loader and debug Ghidra-specific code in Eclipse, while check the semantic correctness of the parser and explore the API more comfortably in Python REPL:
$ python -i test.py portmir
.text 0x20
.data 0x40
.bss 0x80
.loader 0x1000
>>> hex(portmir.section_headers[0].s_vaddr)
'0x10000100'
… or just browse the parsed structures in KT‘s awesome WebIDE.
Integrating the generated Java code with Ghidra was a piece of cake:
- Add Kaitai’s runtime library to the project
- Wrap the Java byte array provided by Ghidra’s ByteProvider with ByteBufferKaitaiStream, and use the appropriate constructor of the generated class
After the Ghidra-Kaitai interface was set, the only things left were setting the default big-endian PowerPC language, letting Kaitai parse the section headers of the XCOFF file, and mapping them to the Program memory. After this, I could immediately see convincing disassembly and decompilation(!) results:
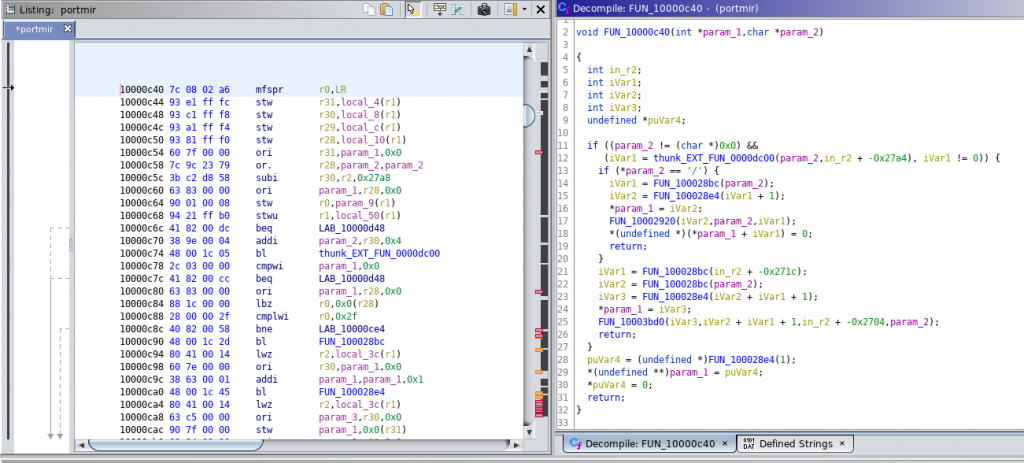
(Mysterious) Symbols of Love
To give Ghidra more hints about the program structure, I proceeded by parsing symbol information. I don’t want to dive deep into the XCOFF format in this post, but in short, there is a symbol table defined by the .loader section of the binary, that holds information about imports and exports, and there is an optional symbol table potentially referenced by the main header for more detailed information. XCOFF can also contain a TOC (table of contents) that contains valuable structural information for reverse engineering if present.
Since the small utility I used for testing only contained a loader symbol table, I implemented parsing for that, and managed to find the entry function of the file, which was not identified during automatic analysis.
To check my results, I also loaded the sample file into IDA, and to my surprise, this tool showed much more symbols than the loader symbol table! I searched for some of the missing symbols in the binary and found a single occurrence of every missing function name inside the .text section:

After a lot of digging (and asking on Twitter) I found that this arrangement matches the Symbol Table Layout described in the specification:
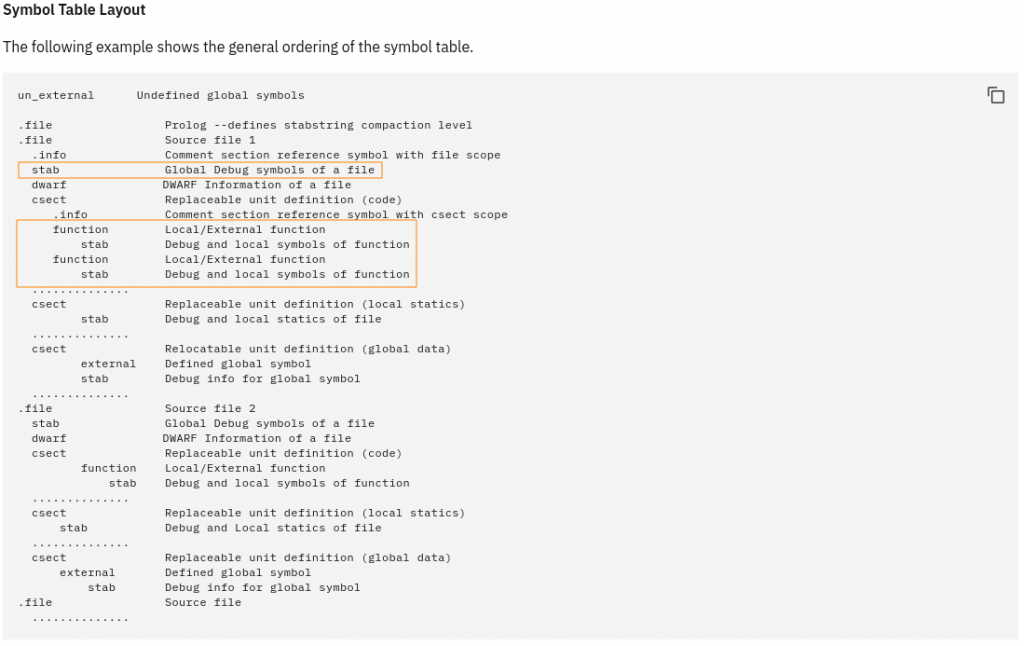
So far, I couldn’t fully decipher this layout, but my working theory is that while the optional symbol table and TOC were removed by stripping, the per-function stabs remained untouched. If so, this is good news for reverse engineers interested in the XCOFF format :)
Update 2021.04.07: As /u/ohmantics pointed out, this is actually the Traceback Table of the function. Proper support for these structures coming soon!
While the parser of this information should be placed in a proper analyzer module, for now, I put together a simple Python script that tries to parse string structures from between declared functions, and renames functions accordingly:

Summary
This blog post showed that Kaitai Struct can be an effective tool to add new formats to Ghidra. Parser development is a tedious and error-prone process that should be outsourced to machines, which don’t get frustrated at the 92nd bitfield definition, and can produce the same, correct implementation for every instance (provided you don’t screw up the parser declaration itself ;) ).
The post allowed a peek inside the XCOFF format too, that seems to worth some security-minded study in parser applications.
We hope that our published code will attract contributors that are also interested in bringing XCOFF to Ghidra or even to other research tools:
Featured image is from Wikipedia (our boxes look much cooler)
.jpeg){kind=link}