
Fuzzy Snapshots of Firefox IPC
In January Mozilla published a post on their Attack & Defense blog about Effectively Fuzzing the IPC Layer in Firefox. In this post the authors pointed out that testing individual components of complex systems (such as a web browser) in isolation should be extended by full-system testing, for which snapshot fuzzing seems like a promising tool. As I’ve been using KF/x – a snapshot fuzzer based on Xen’s virtual machine introspection capabilities – since its first release, this seemed like a perfect challenge to create a realistic demo for the fuzzer and put Mozilla’s suggestions (not to mention my skills) to the test.
This blog post is aimed to show how a complex, real-life target can be harnessed with KF/x, and to highlight some challenges in the snapshot fuzzing space.
But before we dive into these topics, I’d like to highlight the fact that I have zero experience with Firefox, while the majority of this experiment was done in a couple of day’s time. I will approach this experiment as if Firefox was a black-box target from instrumentation standpoint, but I’ll often cut corners by reffering to source code instead of reversing the binary.
I also like to say that sharing one’s failures can provide valuable lessons for others – this is one of the cases when I don’t spare on learning material, so buckle up!
Snapshot Fuzzing with KF/x
KF/x is first and foremost a harnessing tool: it allows capturing a snapshot of a Xen domain (VM), inject a test case into its memory, capture code-coverage information and sink (crash) events up to some predefined point, then revert the state. Collected data is then communicated to the outside world by implementing an AFL-compatible shared memory interface. KF/x can be treated as the fuzzer’s target program, while during each test case a virtual machine is executed and inspected for coverage data. While the primary goal of KF/x was targeting kernels, it is capable of harnessing user-land processes in Linux and Windows as well. The primary use-case of KF/x for me is to target black-box targets with anti-debug functionality on Windows.
As you see, KF/x relies on virtualization to execute whole systems. VM snapshots are based on CoW memory that makes restoring snapshots really fast, while the target can run at close to native speed. While this property is admittedly attractive, we will see that virtualization based instrumentation has some challenges that are easier to solve with emulation based solutions. A great blog post about setting up one of those latter type of fuzzers can be read here (thx for the tip @banyaszvonat!).
You can find more information (including presentations by its author, @tklengyel) about KF/x on it’s GitHub page.
Invalidating Assumptions
Mozilla’s post provides the reader with tempting information about how to start out with fuzzing the IPC layer:
- Public bugs affecting the IPC interface – Investigating N-days is always a good way to get familiar with a target
- Possible snapshot points in the browser’s code flow – Knowing when important things happen is crucial for snapshot fuzzing, esp. when we work with VMs, where (contrary to emulators) the target executes on actual hardware, independently from our introspection code.
I quickly filtered the listed bugs to “The Icon Bug”, which is an OOB read, so
- … it will likely end up in invalid memory access (not a “logic bug”, which would require custom sink definitions for detection)
- … it has a better chance than a UaF to be detected without additional memory access instrumentation (such as ASAN) – contrary to emulator based solutions, we don’t get to inspect memory accesses of the virtualized target by default
I set a up a Debian 10 VM, and downloaded Firefox 61a1 from April 2018, close to the bug report. I also cloned the source code of this version and tried to compile it, but it seemed like the bootstrap infrastructure have moved away from behind this old code. Fortunately the binaries were not stripped, which helped a lot.
The first thing we need to make KF/x work is to create a snapshot of the virtual machine at a point in time, where our controlled input is already loaded in memory, but just before its parsing started. We will mark this state with a breakpoint, and use VM instrumentation to manipulate the input buffer directly in the VM’s memory, then let the system play with it.
While Mozilla made multiple suggestions about the optimal snapshot place, (based on my admittedly sloppy understanding of the corresponding code) I believe the mentioned methods are unfortunately too far from this optimal point, as references to the input data are not directly present. I looked at the crash report instead, where the first call outside the fuzzing harness (Mozilla’s, not KF/x) is PContentParent::OnMessageReceived(IPC::Message const&). This looked like a promising method: one that is called every time a new IPC message arrives. Inspecting the code also confirmed that this is indeed a large dispatcher routine that makes indirect calls to message receiver implementations based on a 4-byte identifier in the form of 0x002d00xx.
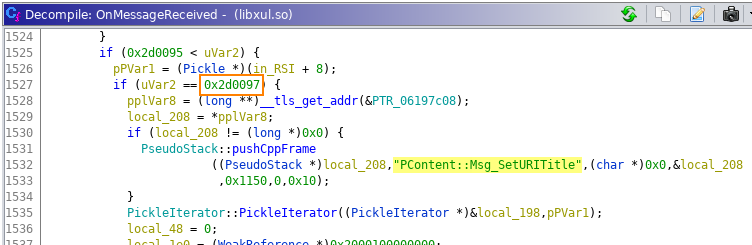
The bug report also included a minimized test case, which looks like this:
00000000 28 00 00 00 ff ff ff 7f 97 00 2d 00 45 6e 76 50 |(.........-.EnvP|
00000010 6c 69 67 6e 75 7b 6c 75 67 6e 73 00 00 00 00 00 |lignu{lugns.....|
00000020 04 00 00 00 01 00 00 00 9b 9a 9a ba 73 00 00 00 |............s...|
00000030 00 78 69 74 63 6f 64 65 65 72 5f 73 6d 78 69 74 |.xitcodeer_smxit|
00000040 63 00 00 72 5f 73 6d 61 |c..r_sma|
00000048
Here we can immediately see the 0x002d0097 message type identifier (in assembly we trust: in source we’d “only” see Msg_SetURITitle) , INT_MAX, and also a likely length value as the first DWORD of the stream. This must be some kind of serialization.
The problem at this point was that the OnMessageReceived method got an IPC::Message object from its caller, while I had a file with some bytes in it. How do I inject this serialized stream into the process, so it will be parsed as expected?
A quick look at the decompiled code revealed that the message type ID is read from an address relative to a register value, and when I checked this address in a debugger, I indeed got something that closely resembled the previous stream structure:
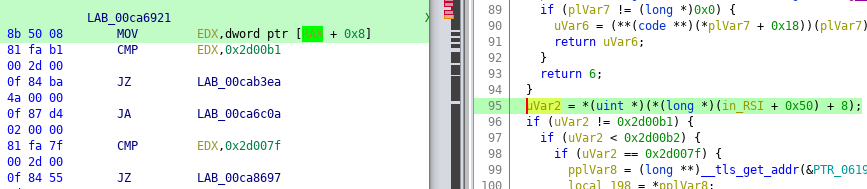

This was enough for me to do the whole harnessing dance, with carefully placing breakpoints in Firefox, noting relevant addresses. Even when I tested the harness with bare KF/x (running without AFL), the minimized test case crashed the process (inside the VM snapshot), while the one I drag out of /dev/urandom did not – this wasn’t a sound proof though that everything was working as expected.
I started suspecting that something is wrong, when I couldn’t find the “offending” bytes in the crashing sample, so that I could make it survive parsing. Then I launched AFL with my slightly modified samples, and noticed that it recorded crashes even when the message type ID was corrupted, so the affected parser could never get invoked.
I assumed that the buffer I was manipulating wasn’t the (only) region of memory that affected the state of the IPC::Message object. In fact, when searching the memory of the process at our supposed snapshot point, we can find dozens of patterns in memory that look like the same serialized message.
In case of my other targets one thing that usually works in similar scenarios is to try and inject modified input to all possible buffers with KF/x, and see in which case(s) the execution path changes. In this case, however, I looked for a different, less brute-force approach, largely because the source code of IPC::Message and its parent classes presented a labyrinth of data structures that wouldn’t necessarily contain the serialized input in a single continuous block of memory.
Learning from prior art
How did Mozilla’s fuzzer feed that byte stream to Firefox, so the bug could be found in the first place? Again, the published crash log quickly reveals that the magic is happening in the ProtocolFuzzer::FuzzProtocol method – the relevant parts are the following:
void FuzzProtocol(T* aProtocol, const uint8_t* aData, size_t aSize,
const nsTArray& aIgnoredMessageTypes) {
while (true) {
uint32_t msg_size =
IPC::Message::MessageSize(reinterpret_cast(aData),
reinterpret_cast(aData) + aSize);
if (msg_size == 0 || msg_size > aSize) {
break;
}
IPC::Message m(reinterpret_cast(aData), msg_size);
// ...
if (m.is_sync()) {
UniquePtr<IPC::Message> reply;
aProtocol->OnMessageReceived(m, *getter_Transfers(reply));
} else { aProtocol->OnMessageReceived(m); }
The important part is that IPC::Message has a constructor that accepts a raw byte stream. Later, the resulting object is passed to OnMessageReceived() (of PContentParenṫ, with some C++ magic), so we were on the right path here.
Interestingly, neither could I find a reference to this magical constructor in the decompiled libxul library, nor with GDB. In source, the “missing” constructor was present of course:
Message::Message(const char* data, int data_len) : Pickle(MSG_HEADER_SZ_DATA, data, data_len) {
MOZ_COUNT_CTOR(IPC::Message);
}
The Pickle reference is part of an initialization list: when an IPC::Message is initialized with a raw buffer in source code, it’s actually the Pickle constructor that’s being called. When breaking on this constructor, we can see that it is invoked by IPC::Channel::ChannelImpl::ProcessIncomingMessages(). Since this method processes messages all the time, it’s worth to set a conditional breakpoint so we’ll only see Msg_SetURITitle (aka. 0x2d0097) messages:
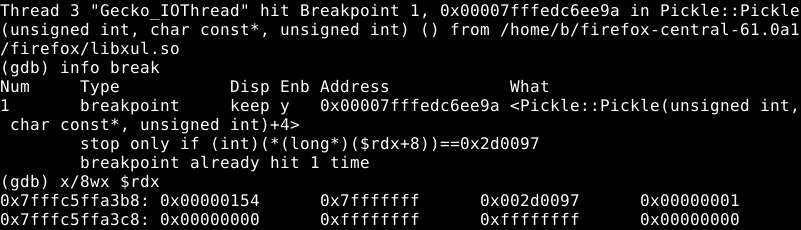
We can confirm this is working by loading any website, so the tab title will change, and the breakpoint will hit.
Interestingly, when I replaced 0x2d0097 message with the published trigger, ProcessIncomingMessages() discarded it, stating that it’d require too many file descriptors, so the bug didn’t trigger. Even when I patched out the check with GDB, an assertation-like method (MOZ_CrashPrintf()) triggered the SEGFAULT, instead of the one mentioned in the original report. With my limited FF knowledge I can’t tell if Mozilla’s fuzzer digs into a “private” interface when calling OnMessageReceived() directly, or there are legitimate ways to do this when running in a sandboxed process.
Anyway, this is enough to harness this beast (well, kind of, we’re far from the end…), and it would be interesting to find out whether some bug could be reached with the above check in place!
Just Harness Already!
OK, so the plan is this:
- Set a conditional breakpoint on the
Pickleconstructor that only triggers when a message with typeMsg_SetURITitleis received. We know that this constructor already performs some interesting parsing. - Put an INT3 (0xCC) breakpoint on an upcoming instruction – this will signal KF/x that it should take a snapshot of the VM. Note the first byte of the instruction, as KF/x will have to restore this value, just as a debugger in the guest would. After this breakpoint is hit, any other breakpoint will trigger the restoration of the snapshot state from dom0.
- Limit execution of the process: my usual approach is to look at the stack trace, and place a breakpoint on some previous return address. This way all of the potential returns of the functions higher in the stack will be covered.
When this is all set up in the guest, we have to start KF/x in setup mode, so it’ll start listen for the first breakpoint interrupt. When we continue execution in the guest the first INT3 triggers the snapshot capture (and the restoration of the original instruction byte).
After this we can start playing with KF/x: when executed outside the fuzzer it just runs until the first breakpoint, displays the crash/no crash verdict, and optionally the recorded instruction trace (–debug). While doing these test runs, I noticed that if the file descriptor check fails, the VM enters an infinite loop. This is because the VM’s device model is removed from the snapshot, so when Firefox attempts to write some warnings to logs the target device is no longer there. This could be solved easily by looking up code addresses noted during harnessing, and using the rwmem utility that comes with KF/x to simply put another breakpoint inside the body of that nasty if(we don't have enough descriptors){} statement, so the harness will treat it as a “stop” event for the fuzz iteration.
The process is shown on the following video:
We can see that we are fuzzing something, and that AFL finds crashes almost immediately. Unfortunately, these are also different assertions, showing that there are several checks in addition to the one for the number of file descriptors before OnMessageReceived() that our serialized message has to survive. By adding new breakpoints to the relevant assertion methods, these results can be filtered (also with putting breakpoints with rwmem), and even performance will grow.
Now that performance is mentioned: When I started these experiments, my VM config and KF/x version were not in sync, so I couldn’t use Intel PT for coverage tracing. Without HW support, KF/x places breakpoints on-the-fly into the target, triggering a context switch at each basic block. This approach is very slow, yielding less than 10 c/s in AFL. After upgrading my system, I could achieve ~3000 c/s with Intel PT, with peaks over 4000. This is not a benchmarking post though.
The new assertions we’re hitting here are mostly related to so called “sentinels”: constant DWORD identifiers in the serialized messages. Fuzzing builds of Firefox disable sentinel checks, so the published trigger was riddled with invalid values that I fixed manually in the serialized file. “Magic” values like these will render an uniformed input generator useless of course, but this is not relevant to our current experiment.
With this “valid” serialized message, I could reach a state where the parser would want to read past the end of the buffer. Pickle objects maintain a pointer to the end of their buffer and one for the current read position. The following screenshot shows that these two pointers are equal, while execution reaches ipc::ReadIPDLParam() that would read past the end pointer:
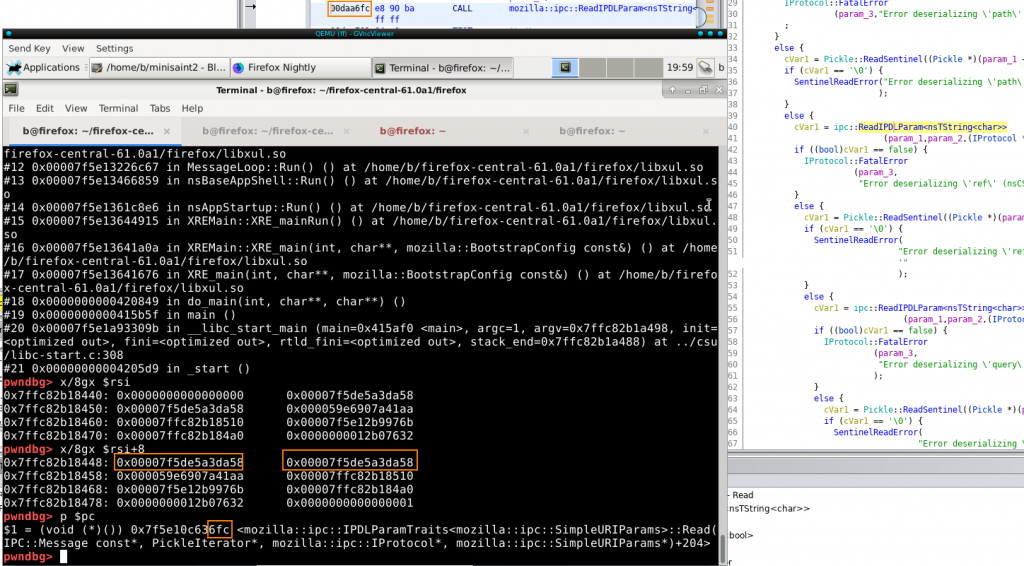
This is not a bug, as the Read…methods of PickleIterator check if they’d read past the end pointer stored in the object, but shows that something is fishy with the object that could cause trouble in later phases of parsing – given that execution can reach that point of course…
It’s also worth noting that this deserialization from the raw buffer to a Pickle happens in a different thread from where we’ve set our original buffer. Multi-threading can make it difficult to match test inputs with observed behaviors, and in case of KF/x we can only hope that no device access happens (remember: we don’t have devices during fuzzing) until the thread scheduler prioritizes the Message parser thread within the same process.
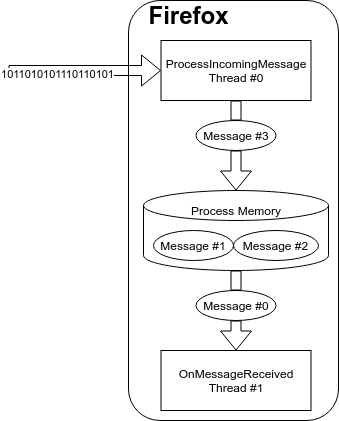
So in summary, while inspecting the original fuzzer helped to identify a part of code where serialized data can be fed to the system, saving a snapshot here is not a good enough to reach the message parsing logic affected by our test bug. It is also pretty clear that the trigger published in the original bug report will not be useful in a standard build because numerous assertions are in the way.
Back to the other side
My little detour on the other side of the message handler wasn’t in vain: I learned a lot about the structure of the Pickles, the Message objects created from them, and the mechanics of message passing between the different threads of the target process. The initial heaps of false positives resulting from the original trigger also made sense now, having dealt with the sentinels and other IPDL format checks.
Based on this, I could handcraft a Pickle object for ProcessIncomingMessages() and catch it when it arrived at OnMessageReceived(). It turned out that the buffer I identified on my first try was in fact the one processed by OnMessageReceived() with a PickleIterator.
The process of harnessing the side of the message parser thread is shown in the following demo:
While the process is basically the same as it was for the message receiver thread, there are a couple of things to notice.
First, a breakpoint is placed to MOZ_Crash_Printf(), which is usually called called when different assertions are hit. The breakpoint here triggers a revert without touching a sink, improving signal/noise ratio.
Second, the execution of libc’s __tls_get_addr() is inspected briefly, for no apparent reason. This is the result of a message from the Demo Gods: when I was recording a previous version of this video, I had an almost perfect shot, where executing the target even with unmodified data crashed. After much frustration I ended up injecting some hand crafted buffers to the target, and confirmed that all calls to this library function crash. A likely explanation for this (taking into account that this problem is not deterministic), is that the memory page holding the library code was paged out when the snapshot was taken, so the page fault handler – hooked by KF/x as a crash sink – got called. A nice summary of this problem and some possible solutions are available here from the HVMI project.
As you can see, manipulating the originally identified buffer when executing OnMessageReceived() results in numerous different execution paths, and even some crashes – which are, again, other assertions. At this point I decided to give this project a break, and write up my experiences, as I felt there’s already much to think about.
Conclusions
So what can one make out of all this? Here are some of my thoughts:
- User input is generally delivered to programs as some kind of serialized stream of bytes (file, network packet, etc.), which is easiest to target with the presented approach. However, interesting functionality may only be reachable via complex in-memory objects – harnessing in such cases may require target-specific tweaking.
- Working with VMI is pretty easy, but figuring out the runtime memory layout of complex objects isn’t. Snapshot fuzzers can be supported by test API’s that accept simple(r) types, and invoke constructors and deserializers internally.
- Copies of user input are often stored at multiple places in memory. It is important to determine early if we target the right address by executing well thought-out test cases and inspecting if our input affects the code flow at all. In many cases, the simplest solutions work best.
- Collecting events from the target VM is a crucial part of virtualization-based snapshot fuzzing. In case of coverage tracking, performance cost of context switching can easily skyrocket. The usual solutions to this are HW assistance (e.g. Intel PT, BTS) or coarser tracking (e.g. periodic sampling; not tracking “boring” paths).
- Test paths may differ from the ones reachable during real execution. This can beneficial for defense-in-depth, but not necessarily for finding exploitable vulnerabilities.
- Bug “enrichment” (like ASAN) for virtualization based snapshot fuzzers looks like an important area to research further.
- The lack of device model introduces some challenges. For example, when reading large files, the entirety of the file may not be present in the memory at once, and fuzzing needs to be split into separate phases. On the other hand, this lack of state guarantees that the fuzzer always returns to the same state and doesn’t leak memory :)
I’m pretty sure, these experiments could be improved, so if you have some ideas (or think I made another mistake somewhere), please reach out!
Finally, I’d like to thank Christoph Kerschbaumer and Christian Holler for their inspiring blog post – I wish we could see more of its kind! I’d also like to thank Tamás K. Lengyel once again for his amazing work on bringing snapshot fuzzing to the masses with KF/x!
Featured image from Prodigy’s official Smack My Bitch Up music video – which is apparently too much for the Brave New Web of 2021.